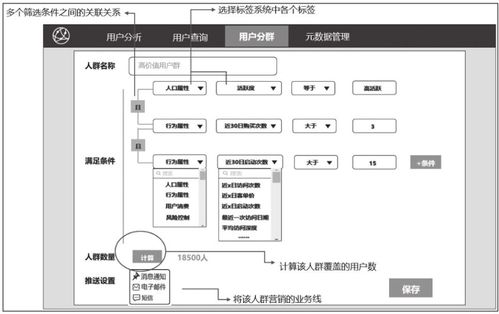
在数字化营销和个性化服务日益重要的今天,用户画像作为核心工具,其标签数据的存储、处理和管理成为企业成功的关键。用户画像通过收集、整合和分析用户的多维度信息,生成如“年龄25-30岁”、“偏好电子产品”等标签,用于精准推荐、风险控制和用户体验优化。本文将深入探讨用户画像标签数据的存储方法、数据处理流程及存储服务的选择,帮助构建高效、可扩展的数据基础。
一、标签数据的特征与存储需求
用户标签数据通常具有高维度、稀疏性和动态更新等特点。例如,一个用户可能拥有数百个标签,但仅部分标签活跃;同时,用户行为变化会导致标签频繁更新。因此,存储系统需满足以下需求:高可扩展性以支持海量数据、低延迟以实现实时查询、以及强一致性确保数据准确。常见的存储方案包括关系型数据库(如MySQL,适用于结构化标签)、NoSQL数据库(如HBase或Cassandra,适合半结构化和水平扩展),以及图数据库(如Neo4j,用于复杂关系分析)。
二、数据处理流程:从原始数据到标签存储
数据处理是用户画像构建的核心环节,通常包括数据采集、清洗、标签化和存储。通过日志、API或第三方工具采集用户行为数据;接着,进行数据清洗以去除噪声和重复项;然后,应用规则引擎或机器学习模型生成标签,例如基于购买记录标记“高价值客户”;将标签数据存入选定的存储系统。整个流程需注重实时性与批处理结合,例如使用Kafka处理流数据,Spark进行批量计算,以确保标签及时更新。
三、存储服务的选择与最佳实践
选择合适的存储服务取决于业务场景。对于需要高并发读写的场景,可选用云服务如AWS DynamoDB或阿里云表格存储,它们提供自动扩缩容和低延迟。对于复杂查询,可结合Elasticsearch实现快速检索。最佳实践包括:设计合理的标签 schema 以优化存储效率、实施数据分区和索引提升性能、以及采用数据备份和加密保障安全。监控存储系统的指标,如吞吐量和延迟,有助于持续优化。
四、未来趋势与挑战
随着AI和物联网的发展,用户标签数据将更加丰富,存储系统需应对数据爆炸和隐私合规挑战。边缘计算和分布式存储技术将兴起,以实现更高效的数据处理。企业应关注数据治理,确保在存储过程中遵循GDPR等法规,平衡个性化与用户隐私。
用户画像标签数据的存储与处理是一个系统工程,需结合业务需求选择合适的技术栈。通过高效的存储服务,企业能释放数据价值,驱动智能决策,最终提升竞争力。